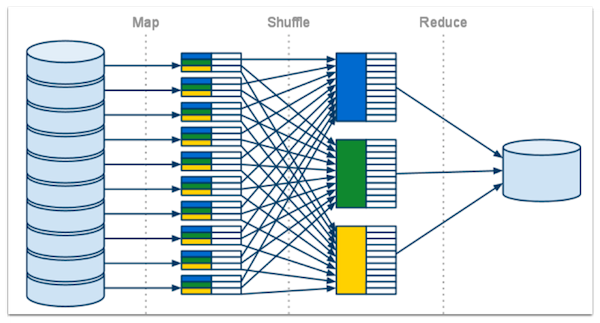
Figure1 MapReduce Overview from https://developers.google.com/appengine/docs/python/images/mapreduce_mapshuffle.png
PREFACE
Let’s continue our previous discussion. Today, we talk about MapReduce framework what/how the underlying mechanisms work when you use Java with Hadoop.
2. MapReduce
n fact, MapReduce concept is not new –it is actually inspired by the map and reduce functions commonly used in functional programming [1] although their purpose in the MapReduce framework is not the same as in their original forms.[2] The key contributions of the MapReduce framework are not the actual map and reduce functions, but the scalability and fault-tolerance achieved for a variety of applications by optimizing the execution engine once.
However, by understanding the original form of the map and reduce functions, you can catch it the whole idea much faster. Let’s start with Python’s map and reduce function to get you warm up.
If you’re familiar with Python, you must know about map() function that performs some operation on each element of an iterable (the following Python tutorial extracted from [3][4]). It returns a list containing the result of those operations. Here is the general form:
# f is a function that takes one argument and returns a value.
# S is any iterable.
map(f, S)Let’s see an example.
>>> def abc(a, b, c):
... return a*10000 + b*100 + c
...
>>> map(abc, (1, 2, 3), (4, 5, 6), (7, 8, 9))
[10407, 20508, 30609]-
Define a function abc to put a, b and c into a equation.
-
Use map() to apply abc() with multiple arguments - 3 turtles of a set of sequence.
Now you know about the usage of map(), let’s start with reduce() in python. The function reduce()continually applies the function func() to the sequence seq. It returns a single value.
reduce(f, seq)
# f is a function that takes one argument and returns a value.
# seq is a list of sequenceso If seq = [ s1, s2, s3, ... , sn ], calling reduce(func, seq) works like this:
At first the first two elements of seq will be applied to func, i.e. func(s1,s2)
The list on which reduce() works looks now like this: [ func(s1,s2), s3, … , sn ]
In the next step func will be applied on the previous result and the third element of the list,
i.e. func(func(s1, s2),s3) The list looks like this now: [ func(func(s1, s2),s3),… , sn ]
Continue like this until just one element is left and return this element as the result of
reduce()
Let’s see the example that apply lambda function to simply make x + y and the illustration of reduce process in the figure below.
>>> reduce(lambda x,y: x+y, [47,11,42,13])
113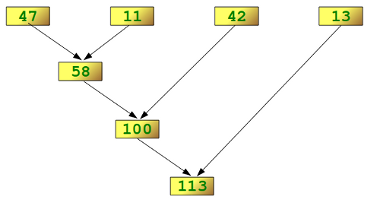
Figure2 breakdown of the steps of the calculation from http://www.python course.eu/images/reduce_diagram.png
It’s time to put Python map and reduce together
Let’s calculate:
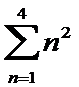
Here is our code to apply map to do square operation to each element of the iterable and finally apply reduce to continually perform sum operation to return the a value.
l = [1, 2, 3, 4]
def square(x):
return x * x
def sum(x, y):
return x + y
reduce(sum, map(square, l))Video breakdown of the steps of the calculation
Okay, you guess you guys should catch the idea a little bit. Let’s go the real MapReduce programming model in WSCs.
So let’s recall what WSCs are composed of, yeah, physically, you’ve got a collection of 10,000 to 100,000 severs or even more and networks (Ethernet or even costly InfiniBand) connects them together. Okay, the question is how you have multiple servers work together to process, let’s say, 100GB workload of dataset. MapReduce programming model is basically to make these physical 10,000 servers as one Single gigantic machine from programmer‘s viewpoint. So you can run very large applications (Internet service) such as web search, email, video sharing and social networking.
Let’s start from programmer perspective in MapReduce execution. At the beginning, you basically will have a dataset and then you may use Jave to make a class that extends hadoop mapper class. Next, the programmers can put their code in two phases – Map and Reduce (In Java, put your work on your defined map and reduce function).
In Map phase where basically slices your dataset into “shards” or “splits” and distribute to workers (will talk about later) and then compute set of intermediate key/value pairs
Map: (in_key, in_value) --> list(interm_key, interm_val)
map(in_key, in_val):
// DO WORK HERE
emit(interm_key,interm_val)In Reduce phase where combines all intermediate values for a particular key and produces a set of merged output values (usually just one)
Reduce: (interm_key, list(interm_value)) --> list(out_value)
reduce(interm_key, list(interm_val)):
// DO WORK HERE
emit(out_key, out_val)We use the example of wordcount to explain. Doc content is a the dataset and in Map phase we want to split each word from the document
Map phase: (doc name, doc contents) --> list(word, count)
map(key, value):
for each word w in value:
emit(w, 1)so if the content is “ I do I learn”, the above code will output the list like [(“I”,1),(“do”,1),(“I”,1),(“learn”,1)]
In Reduce phase, we want to know the total count of each word, the arguments will contain a key, which is a single word and a list of the counts.
Reduce phase: (word, list(count)) --> (word, count_sum)
reduce(key, values):
result = 0
for each v in values:
result += v
emit(key, result)The result is like (“I”, [1,1]) --> (“I”,2)
Let’s see the underlying implementation of MapReduce framework.
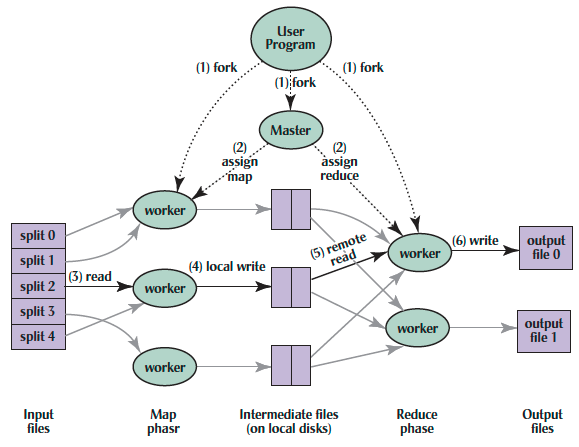
Figure4 Execution overview from [1]
Let’s break the execution down based on overall flow from [1]:
-
The MapReduce library in the user program first splits the input files into M pieces of typically 16 megabytes to 64 megabytes (MB) per piece (controllable by the user via an optional parameter). It then starts up many copies of the program on a cluster of machines.
-
One of the copies of the program is special – the master. The rest are workers that are assigned work by the master. There are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one a map task or a reduce task.
-
A worker who is assigned a map task reads the contents of the corresponding input split. It parses key/value pairs out of the input data and passes each pair to the user-defined Map function. The intermediate key/value pairs produced by the Map function are buffered in memory.
-
Periodically, the buffered pairs are written to local disk, partitioned into R regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
-
When a reduce worker is notified by the master about these locations, it uses remote procedure calls to read the buffered data from the local disks of the map workers. When a reduce worker has read all intermediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together. The sorting is needed because typically many different keys map to the same reduce task. If the amount of intermediate data is too large to fit in memory, an external sort is used
-
The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encountered, it passes the key and the corresponding set of intermediate values to the user’s Reduce function. The output of the Reduce function is appended to a final output file for this reduce partition.
We use the illustration in Figure to animate the process (simplified version).
Video1 the execution flow in video from UCB CS 61C: Great Ideas in Computer Architecture.
One thing we need to highlight is the actual duration of the whole tasks is not only execution time of map and reduce tasks assigned to each worker server but also you must count the time of the central role of master to coordinate workers by scheduling the idle worker and notifying them during the transition and the time for data shuffle and data fetch to local HDD.
The figure below points out:
- Master assigns map + reduce tasks to “worker” servers
- As soon as a map task finishes, worker server can be assigned a new map or reduce task
- Data shuffle begins as soon as a given Map finishes
- Reduce task begins as soon as all data shuffles finish
- To tolerate faults, reassign task if a worker server “dies”
- Actual worker time depends on the slowest worker to finish its task.
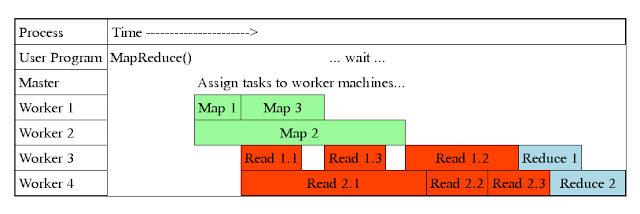
Figure6 the breakdown of the execution time from
Before we finish the tutorial today, we steal a look at some Java and Python example codes that we’re going to elaborate in next article for hands-on of Hadoop and Spark with grimace The figure actually shows wordcount example implemented by Java in Hadoop, okay you see you need to put a lot of code to finish just one thing.

Figure7 WC example in Java
Let’s see another example by Spark Python API. It looks shorter and simpler, right.

Figure8 WC example in Python
We’re going to end here. But in next article – Part 3 Java in Hadoop and Python in Spark, we’ll use the more codes to let you practice what they actually work.
REFERENCE
[1] “Our abstraction is inspired by the map and reduce primitives present in Lisp and many other functional languages.” -“MapReduce: Simplified Data Processing on Large Clusters”, by Jeffrey Dean and Sanjay Ghemawat; from Google Research
[2] Lämmel, R. (2008). “Google’s Map Reduce programming model — Revisited”. Science of Computer Programming 70: 1.doi:10.1016/j.scico.2007.07.001.
[3] Python 2.7 quick reference https://infohost.nmt.edu/tcc/help/pubs/python/web/map-function.html
[4] Python tutorial - Lambda, filter, reduce and map, http://www.python-course.eu/lambda.php