PREFACE
In today article, we’re going to expose you the programming models in WSCs, which is the well-known MapReduce framework you may have heard of it already. The article today is divided into three parts: firstly talk about a background of parallel computing, then go over some theory part of MapReduce and lastly we goes to the core part today which is actually a hands-on in Hadoop and Spark to let you understand these two popular frameworks nowadays in WSCs – Java with Hadoop and Python with Spark.
1. BACKGROUND
As the last article mentions, today Internet service not only must have ability to handle the faults from high hardware component fault rates (any components will probably go wrong, hard drive, cooling fan, power supplies, DRAM and server itself…etc), software inherited bugs and discrepancies in latency due to using 2 layers network but also need to take advantage of the parallel and distributing computing power by WSC. After all, this is reason we create WSC to handle the evolving massive workloads from internet service.
In term of WSC computing, it’s basically broken into two parallel computing fields: Request-Level Parallelism (RLP) and Data-Level Parallelism (DLP). Let’s start with RLP.
1.1 Request-Level Parallelism (RLP)
The prominent example for RLP is Web Search engine (e.g. Google search) which provides the search service with user-made query to look up the data like webpage and image. The popular search engine like Google or social network, such as Facebook may need to handle hundreds of thousands of requests per second from multiple types of computing devices such as laptop and cellphone via different bandwidth of the networks.
Such requests are basically independent and informational, which means they mostly involve read operation to database but rarely involve read-write sharing or synchronization across request. Therefore, we are easier to partition our computation resource across different requests and even within a request.
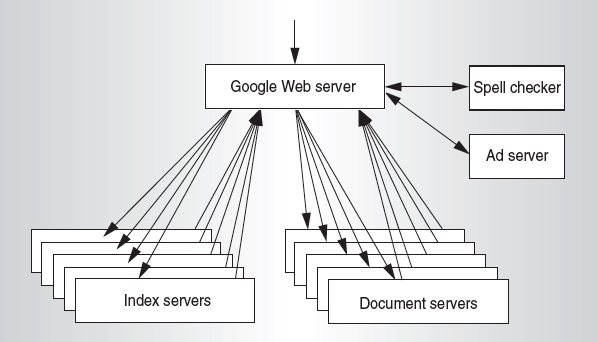
Take Google Query-severing architecture for example (see the figure2): Google uses multiple data replications for its index server and document server to extend its service performance and availability. Of course, Google also have a set of Web servers with load balance which biases the sharding policy to equalize the amount of work per server in order to reduce the response-time variance.
For demonstration, we simulate what typically search engine works when user makes his query to Google search engine
First, google “Paul Yang” in the search bar, you can immediately notice 138,000,000 results in 0.38 secs.
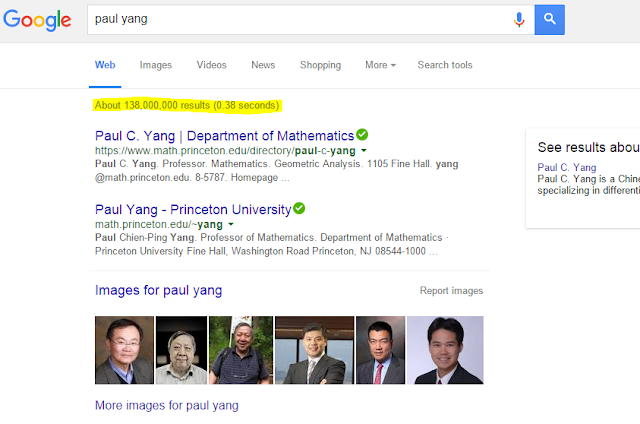
So let’s break down what happened inside:
-
When you key in “Paul Yang” in your browser, the http request goes to the closest Google WSC based on DNS server
-
Front-end load balancer directs request to one of many arrays (cluster of severs) within WSC
-
Within array, select one of many Goggle Web Servers(GWS) to handle the request and compose the response pages
-
GWS communicates with Index Servers to find documents that contains the search words, “Paul”, “Yang”
-
The index server returns document list with associated relevance score
-
In parallel, Google Adwords system runs auction for bidders on search terms and WSC also gets other relevant data like image and videos of Paul Yang
-
Use docids (Document IDs) to access indexed documents
-
Compose the result page you’re seeing in Google.
-
Result document extracts (with keyword in context) ordered by relevance score (here the well-known PageRank algorithm works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites [2] ).
-
Sponsored links (along the top) and advertisements (along the sides) are composed.
-
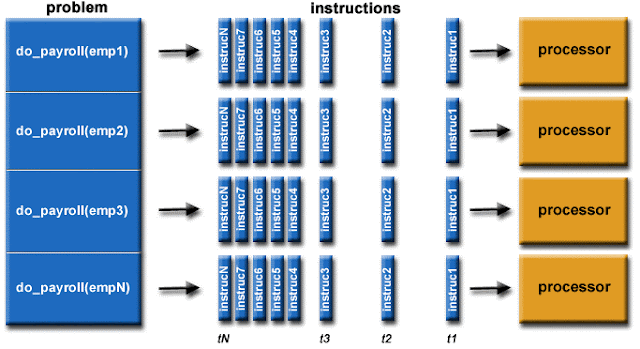
Based on the processes above, you can see that implementation of Request-Level Parallelism for WSC is to make use of three strategies - Randomly distribute the entries, Make many copies of data (a.k.a. “replicas” for index and document server) and Load balance requests across replicas, all components combined to fulfill RLP in WSCs.
In addition, when seeing into the replication technique in this application, we can see Redundant copies of indices and documents not only help to breaks up search hot spots, e.g. “Taylor Swift” to increases opportunities for request-level parallelism but also makes the system more tolerant of failures which means even one node of index and doc sever fails, the request can be processed by other replicas.
1.2 Data-Level Parallelism (DLP)
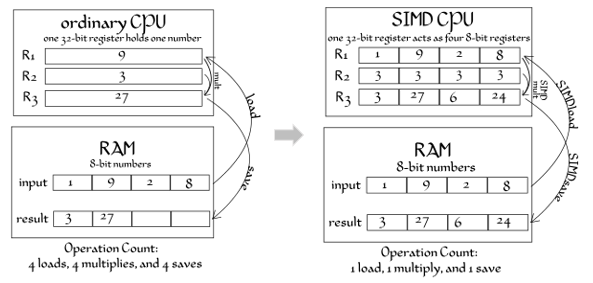
When talking about DLP, I guess many folks should think of SIMD instruction in Figure4, such as SSE by Intel or 3DNow by AMD [1] inside CPU and GPU processor to supports data-level parallelism in a single machine. The common example to use SIMD is to do a lot matrix multiplication in memory.
However, DLP in WSCs actually supports data-level parallelism across multiple machines with MapReduce as the programming model and interface and scalable file systems like GFS for dynamic distribution. The figure shows when you want to train the machine learning algorithm - Convolutional neural networks (CNNs [6] ) with images across multiple disks, which can be achieved by using MapReduce in WSC.
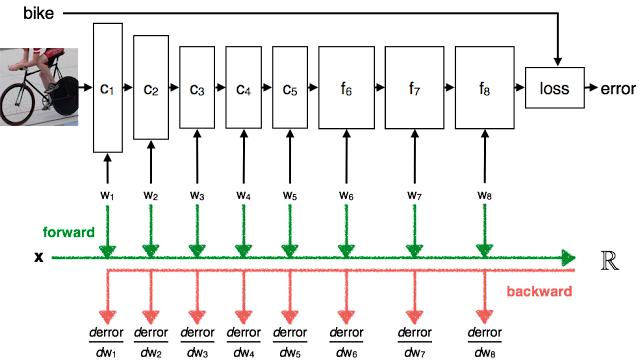
So let’s start our core topic – MapReduce. It’s basically a simple data-parallel programming model and implementation for processing large dataset. Users specify the computation regarding a map function and a reduce function but its underlying runtime system is actually processing the complex tasks as following
- Automatically parallelize the computation across large scale clusters of machines.
- Handles machine failure
- Schedule inter-machine communication to make efficient use of the networks
You can treat the system underlying MapReduce like Hadoop is OS for cluster-level for resource management and computing task scheduling and MapReduce is pretty like the abstraction model like System V API used to simplify the programming effort and hide all the internal complexity. In addition, such cluster-level OS basically is able to be scalable to large volumes of data and run on large clusters of commodity hardware, so it can be very cost-efficient and suited for WSCs.
Let’s see the several examples that what the big internet companies use MapReduce for.
At Google
- Index construction for Google Search in Figure
- Article clustering for Google News
- Statistical machine translation
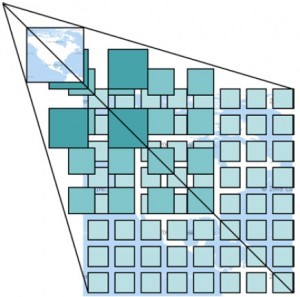
- For computing multi-layers street maps in Figure

At Yahoo
- “Web map” powering Yahoo! Search
- Spam detection for Yahoo! Mail using machine learning, such as Naïve Bayes classifier [3][4] in filtering.
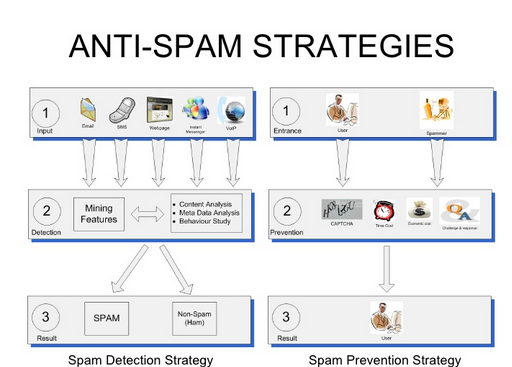
Figure8. Spam detection from http://www.slideshare.net/pi3ch/evaluation-of-spam-detection-and-prevention-frameworks-for-email-and-image-spam-a-state-of-art
At Facebook
- Data mining in Figure
- Ad optimization [5]
- Spam detection
From Facebook lexicon, you can observe the pattern of the keywords, for example, Figure points out that people used to have frequent party and hangover in late Oct and late Dec in 2007, which basically reflects people situations in holidays and can be used for prediction data for merchandiser to better manage the distribution of the relevant goods.
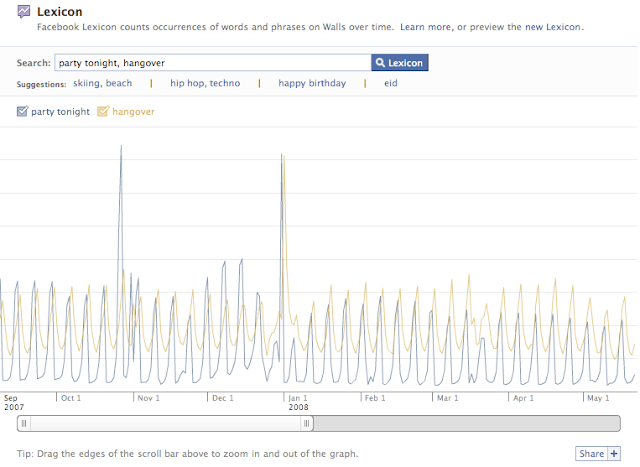
Figure9. Facebook Lexicon from www.facebook.com/lexicon
REFERENCE
[1] Intel AMD 3DNow! Instructions https://en.wikipedia.org/wiki/3DNow! ;
[1] The Intel Intrinsics Guide for Intel SSE, AVX, AVX-512, and more https://software.intel.com/sites/landingpage/IntrinsicsGuide/
[2] “Facts about Google and Competition”. Archived from the original on 4 November 2011. Retrieved12 July 2014.
[3] Naive Bayes classifiers, https://en.wikipedia.org/wiki/Naive_Bayes_classifier
[4] Konstantin Tretyakov , Machine Learning Techniques in Spam Filtering http://ats.cs.ut.ee/u/kt/hw/spam/spam.pdf
[5] Facebook turns user tracking ‘bug’ into data mining ‘feature’ for advertisers http://www.zdnet.com/article/facebook-turns-user-tracking-bug-into-data-mining-feature-for-advertisers/
[6] UFLDL Tutorial Convolutional Neural Network, http://ufldl.stanford.edu/tutorial/supervised/ConvolutionalNeuralNetwork/